My CS1 Backend
(Technical)14 min read
This post is first in a series. Here’s an index of the rest:
- The Need for Jeed: How and why we run untrusted Java code in a secure in-process sandbox. (tl;dr: It’s fast.)
I’ve created an interactive, immersive, and effective online learning experience for my CS1 students. Students experience the website frontend first-hand—where they play with code; learn directly from instructors and course staff; complete programming and debugging exercises; take quizzes; get help; and view the results. But I’ve never documented the backend infrastructure that supports this online educational experience.
It’s time! Over a series of future posts, I’ll share all of the gorious(1) details of how I created this learning environment.
I’m doing this now for several reasons. First, in my fifth year teaching CS1, and fourth semester teaching online during the pandemic, I finally have time. Many of the tools and systems that I’ll describe emerged over multiple years, with some of the earliest dating back to the summer of 2019. Summer and fall 2020 was a huge push to transition the course into the new online format, and more work went into adding Kotlin as a language option in fall 2021. But at this point the course materials and systems are as stable as they have been in several years, so it seems like a good time to document what I’ve done.
Second, I’m also starting to make the transition from “What have I done?” to “Look what I’ve done!” The push to the new online format that I created for Fall 2020 and creating all of the new content for that semester nearly crushed me. There were some very dark days, and I wondered at times if I had taken on way more than I was capable of. I’ve gotten used to little fires everywhere in my course infrastructure, but Fall 2020 was a conflagration. I thought that I had done enough prep work so that adding Kotlin as a language option for Fall 2021 would be straightforward. It wasn’t, and the semester became another tough slog.
And then, all of a sudden, things calmed. A lot of the course content is set up already, and although we’re still making changes and improvements, they’re new sentences, not entire chapters. At this point the systems I’ve created to support the class are well-tested, stable, and relatively—if definitely not entirely—bug-free. I no longer sit nervously by my computer during our Tuesday quizzes waiting for the quiz system to crash(2), or wonder why the homework autograder keeps running out of memory and restarting(3). (Of course, between drafting and releasing this essay, we had another brief hiccup with the homework autograder. Doh!)
It helps that my class is smaller in the spring—700 students now instead of the 1400 I had last fall. But overall things are just working. Although I’m at least partially convinced that the simple act of stating this publicly will cause my Kubernetes cluster to throw a certificate error, my database backups to vanish, and all my students to drop the course. Knock on wood!
But my main motivation for delving into these details is that I’d like to show other tech-savvy educators what’s possible, and maybe inspire them to get out there and create and build.
Most of what I’m going to describe are things that I built myself. I did have some help from some very talented students, and I’m excited to highlight their contributions. But most of these tools and systems are designed, implemented, and maintained by me.
I’m not saying this (entirely) to brag. I am proud of what I’ve created, and know how much work went into it. But it is also truly remarkable what one determined developer can accomplish today—supported by the tools, frameworks, libraries, and community of modern technology and the open-source movement. So even if I’ve authored most of the code, I didn’t do this alone.
Overall I create teaching tools for the same reason that I teach computer science. I tell my students that, by learning computer science, they can create things that change the world. I don’t just say that—I believe it. And, as someone who knows computer science, I have the opportunity to change it as well.
But why? Not why now—just… why? I suspect some of you are asking yourselves that question. Technology has come a long way. Aren’t there great tools for teaching introductory computer science? Why not just use them, rather than creating your own? Wouldn’t it be a better use of your time to spend less time writing code, and more time working directly with students?
These are fair questions. As I continue this series of posts and examine each system that I’ve created in turn, I’ll try and highlight how it compares with the alternatives. However, overall I’ve created new tools and systems for four primary reasons:
-
Nothing similar existed. While there is a lot of overlap between teaching technology and using technology, there are certain problems that are unique to educational settings. I’ve spent a fair amount of time on several problems that are somewhat unique to introductory computer science, including how to run small pieces of untrusted Java code written in the browser quickly and safely, now publicly available at https://jeed.run; how to accelerate authorship of the kind of small programming problems we write in CS1; how to provide good code quality feedback so that students can learn to write good code, not just correct code; and so on.
-
Existing solutions aren’t great or miss opportunities. Could we do embed live coding videos in our materials, like everyone else does(4)? Sure. But building our own animated editor component has both made our live coding walkthroughs more interactive, while also allowing course staff to contribute to the course content in new ways. Could we just use Zoom or some other videoconferencing solution to help students remotely? Sure. But building our own help system on top of Jitsi has allowed our staff to work more efficiently, made student queueing more fair, and allowed us to experiment with new online support policies and procedures.
-
My time is valuable. Creating course content is one of my primary responsibilities as an instructor, and several major development efforts have helped make my creation processes much more efficient. It is now easier for me to create high-quality interactive online materials, and way easier for me to create new small programming exercises. I have the good fortune to be able to make long-term investments into my CS1 course, allowing me to invest the time and energy needed to make existing approaches much more efficient.
-
I’m sort of good at this. Different people bring different talents and abilities to their teaching. I’ve been fortunate that the last two decades of my training in technology have left me with the skills and abilities that I need to create new things for my courses. That’s my superpower, and I think it’s important for me to use it. I’m also very fortunate to have the autonomy and infrastructure support at the University of Illinois I need to support my work. Surprisingly, that’s not true everywhere! Talk to a few techy univeristy educators and you’ll quickly hear stories of critical infrastructure running on retired personal laptops, university mandates requiring the use of poor-quality education technology(5), institutional resistance to new ideas, and a lot of other barriers to innovation. There’s probably enough here for a separate essay, but suffice to say for now that I’m very lucky to be at an institution that both allows and supports my creative vision for computer science education.
It’s also worth pointing out that, once you start to aggregate all the different services you need for a course together, the opportunity to create a fully-integrated experience does encourage you to just finish the job. A few things that I’ve built were inspired by the idea of simply being able to more tightly integrate them with the rest of our site. Sometimes I find ways to customize them to the needs of my class. But I’m not going to claim that our containerized autograder is that different than anyone else’s containerized autograder(6). It’s not.
At this point I’m using only the following off-site services or third-party tools during production, with a strong preference for things that are open source, can be self-hosted, and if not, are at least free or cheap:
- Google login for authentication
- YouTube for video embedding
- Discourse for my course forum(7)
- Gravatar for student and staff photos
- Jitsi as the backend for our online help site
- Otter.ai to caption our interactive walkthroughs
All these are examples of great low-cost tools that I have no interest in trying to replicate. They all do one thing, and do it well. Just to be clear, my course infrastructure also leverages many more open-source libraries and software tools, and I use a bunch of other tools and services during development.
Hosting, Frontend, DatabaseHosting, Frontend, Database
I’ll start by providing an overview of how backend is hosted, and then briefly describe the database and frontend components.
My CS1 backend is currenly deployed on 21 cloud servers. All servers are virtual machines with 4-core virtual CPUs and 8GB of RAM. They constitute three distinct groups based on their function:
- 2 frontend machines with public IP addresses and moderate amounts of storage. One serves static content for the course website and proxies into our private cloud. The second runs our Discourse forum and Discourse forums for a few other things. These are the only two machines that are publicly routeable.
- 3 database machines with larger amounts of storage joined into a MongoDB replica set.
- 16 cloud workers with small amounts of storage joined into a single Kubernetes cloud. This is where I deploy and manage all backend services, which receive requests via the frontend and persist state in the database. The small drives on these machines support a distributed filesystem created using Rook Ceph, to provide persistent storage to a few services that need it.
This is more than enough compute to support thousands of students, while leaving enough left over to support experiments and useful public-facing systems. Could I get by with fewer machines? Probably. But machines are cheap, and optimization time is expensive, and so overprovisioning here seems like the right move. Spare capacity provides me with the opportunity to try new things and supports useful public services and tools like https://jeed.run and https://learncs.online.
DatabaseDatabase
I use MongoDB. So shoot me. I take nightly backups.
FrontendFrontend
With a few exceptions, all student interaction is through the main course website: https://www.cs124.org/. That’s where students log on to work through the daily lessons, experiment with code, complete the homework problems and other exercises, take quizzes, and view their project scores. Students in my class do most of their programming directly in the browser, including all of the daily homework problems and weekly quizzes. They do complete an Android development project during the second half of the semester, which is done in Android Studio.
The course website is a completely static site built using Gatsby. I’m fed up with Gatsby and am in the process of transitioning to NextJS, which I’ve been using for this site, as well as the forthcoming public version of CS 124, https://learncs.online. But the site will remain largely static. I author most content using MDX. I’ll write this up in more detail in another post.
Backend ServicesBackend Services
Now let’s get to the fun stuff! My CS1 backend consists of the following microservices, both described and using their internal development names. Here are the ones that are directly involved in supporting the web frontend:
- Site usage tracking (
element-tracker), a fine-grained site activity logger - Identity management (
personable), including both periodic tasks and a web API, because it’s frustratingly difficult even to just figure out who’s in my class at any point in time - Content delivery (
shareable), which allows instructors and staff to update recorded content for our interactive walkthroughs and videos - Homework autograding (
questioner), one of the more novel systems we’ve created that includes both innovative authoring and evaluation components making it easy to write and deploy Java and Kotlin homework problems, and provides both correctness and code quality feedback to students - Debugging challenge grading (
stumper), a new component supporting a new style of debugging question that we are using for the first time this semester - Quiz delivery and proctoring (
questionable), an appropriate name for a system that I probably shouldn’t have built myself but which works well enough, and makes it much easier to write, deploy, and proctor online quizzes - Editor synchronization (
mace), which saves student work in many of the embedded online editors used heavily throughout our site—a must if you are going to have students doing most of their work online - Online help site (
helpable), which maintains a queue of student help requests and connects students and staff via the Jitsi videoconferencing system - JVM playground backend (
jeed), our fast online Java and Kotlin code runner, which supports all of the many playgrounds embedded throughout the site, the interactive walkthroughs recorded by our course staff, and our homework autograder (discussed in Part 1 of the series) - And the miscellaneous API server, a dumping ground for course-specific endpoints and small experiments that don’t and might never require their own microservice
In addition, there are a few services and data pumps that aren’t accessed directly through the website, but are still crucial to the student experience:
- Project autograding, our containerized autograder, triggered by GitHub webhooks
- Data pumps for logging messages generated by our Gradle and IntelliJ plugins, which provide increased visibility into student work on the Android project
In the essays that follow, I’ll go through most of these services one by one. Behind pretty much every one, is an interesting story—some about new opportunities, some about institutional dysfunction, some about deployment challenges or fun debugging experiences.
How It All Comes TogetherHow It All Comes Together
Before finishing, I wanted to show an example that involved as many of our backend services as possible. Given that I teach a course on computer science and programming, and students do their development in the browser, many of our services converge at the Ace in-browser editors that appear throughout the site.
Here’s one example, taken from a practice problem that appears in our first lesson on recursion. Note that this is the staff view, not the student view. A small bit of the problem description is not visible at the top of the screen.
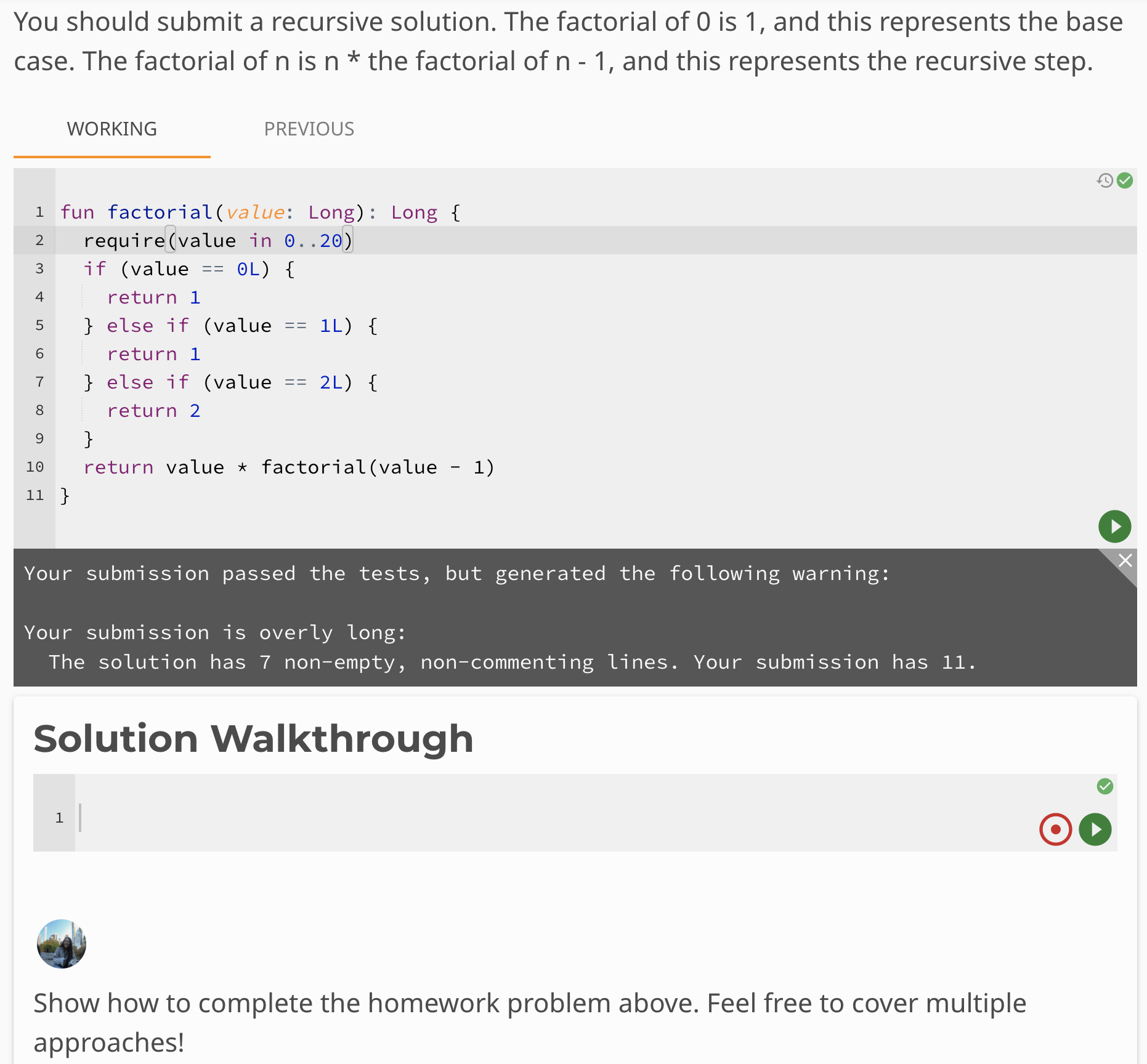
Visible above are integrations with at least four of our twelve backend services:
- (1)
maceis synchronizing the editor contents, as shown by the green check mark and undo icons in the top right - The play button triggers autograding by our (2)
questionerservice, itself built on top of (3)jeed, and providing code quality feedback as shown in the output window - The solution walkthrough and in-browser recording capabilities are provided by (4)
shareable - And, making less visible contributions, user and role management is being done by (5)
personable, site usage data tracked by (6)element-tracker, and if the student needs help, there’s a big “Get Help” button just offscreen that can connect them to our course staff via (7)helpable
Next UpNext Up
In the next installment of this series, I’ll dive into one of the oldest and most central parts of our backend: jeed, our fast Java and Kotlin execution sandbox and overall code analysis toolkit.
Jeed is also something I’ve been able to split out for independent usage, and you can find and use it here: https://jeed.run/.
This post is first in a series. Here’s an index of the rest:
- The Need for Jeed: How and why we run untrusted Java code in a secure in-process sandbox. (tl;dr: It’s fast.)